VideoMatrix
A full video production crew — writer, director, editor — in one matrix.
VideoMatrix is a complete video production team: AI agents that script, storyboard, generate, render, and publish — reasoning through every stage the way a writer, director, and editor would. You bring the idea; the matrix runs the production. Every cut is held for human approval before it ships. Runs on SovrinOS sovereign inference or any LLM you connect.
For Content teams, media operations, agencies, creators, and brands running multi-channel video.
Software you
operate.
VideoMatrix is working software, not a black box. You get a workspace built for the human experience, supervision and approval gates that keep you in control, and AgentChat — talk directly to the matrix to direct, question, and review its work.
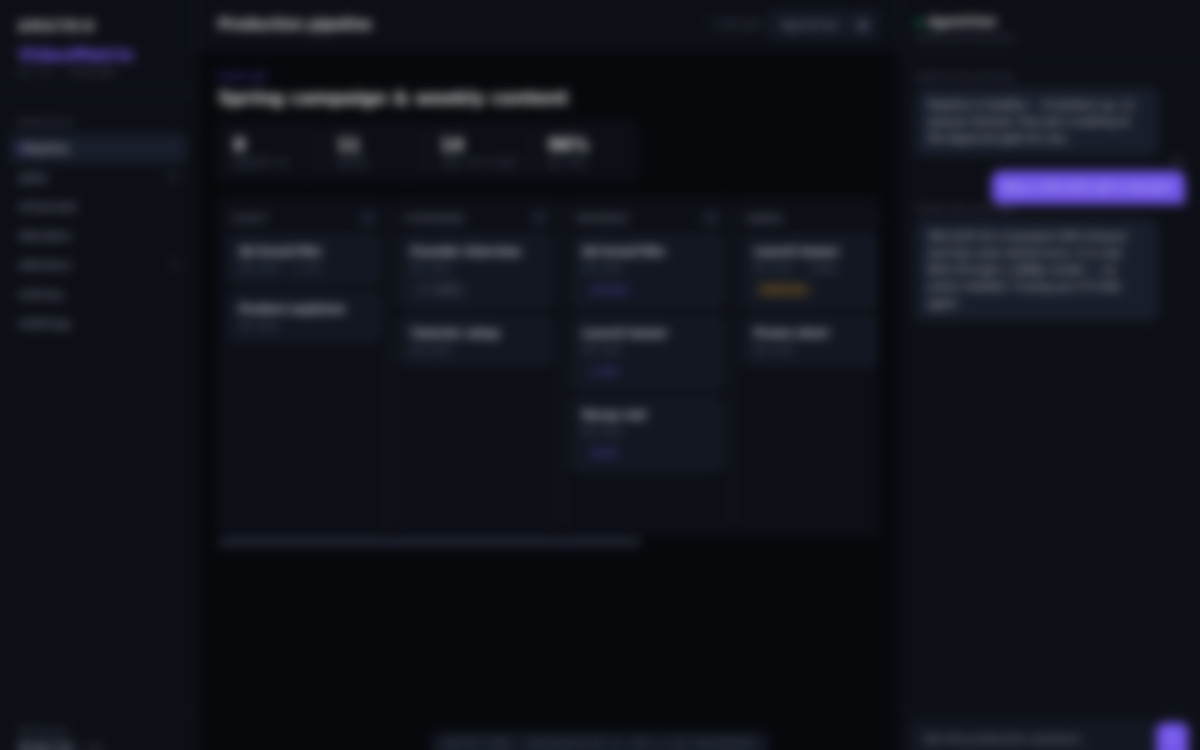
What it
does.
Scriptwriter & storyboard
Agents develop the script and storyboard from a brief the way a writers' room would — structure, beats, and shot list.
Direction & generation
The matrix sets up each shot and runs inference, reasoning about look, pacing, and continuity across the piece.
Render & post-production
Durable render and edit jobs assemble the final cut; long-running jobs retry and isolate failure per stage.
Approval before publish
Nothing reaches an audience until a person reviews and approves the cut — the matrix never publishes on its own.
Multi-platform publishing
Approved videos go out to every channel from one place, formatted per platform.
Production assistant & cost analyst
Ask the on-call agents about job status, failures, and exactly what each production is costing.
A production
pipeline.
- 01Script
- 02Storyboard
- 03Inference
- 04Render
- 05Approval
- 06Publish
Agents you can
talk to.
Diagnoses render failures, stuck jobs, and inference routing
Explains inference spend by token, second, rig, and model
Bring
your model.
Every matrix is LLM-agnostic. Run it on SovrinOS for sovereign inference, on SovrinOS Desktop to run the model locally on your own hardware, or connect any major model — you choose per workspace.
AMatrix's sovereign inference — runs the LLM on dedicated GPUs in Montreal. Your data stays in Canada, on AMatrix infrastructure, and is never sent to a third-party model.
Runs the LLM locally on your own hardware — fully sovereign, on-device or air-gapped. The model and your data never leave your machine.
Connect your Anthropic API key from the integration settings.
Connect your OpenAI API key from the integration settings.
Connect your Google AI API key from the integration settings.
Bring any OpenAI-compatible model endpoint through the integration settings.
When you connect a public model like Claude, ChatGPT, or Gemini, AMatrix anonymizes the content before it is sent — identifying and sensitive details are stripped, so they are never exposed to a third-party model. With SovrinOS, nothing leaves AMatrix infrastructure or your own hardware at all.
SovrinOS and SovrinOS Desktop are the sovereign options — running the model locally or on AMatrix's own GPUs — and are never required. LLM connections are configured per workspace.
Plans for
this matrix.
Hire a full video production crew that turns ideas into finished, approved video — script to publish.
50% off your first 90 days New customers who start before October 31st, 2026 — Start and Team / Growth plans. See full pricing →
Ethics
rubric.
Axes scored
- Truth
- IP/rights
- Consent
- Deceptive editing
- Brand safety
- Accessibility
Prohibited
- Deepfake of real people without consent
- Misleading factual edits
- Copyright laundering
- Impersonation
Required gates
- AI disclosure where regulated
- Rights-cleared assets only by default
AMatrix agents are decision-support tools. Outputs may contain errors and require human review before action.
Ready when
you are.
See plans above · Business and Enterprise onboarding handled directly with the AMatrix team.